
Azure Synapse Analytics oder auch kurz Synapse ist eine vereinheitlichte Datenanalyse Plattform. Das System bietet die Möglichkeit, grosse Datenmengen zu analysieren.
Die Plattform besteht, wie in Azure üblich, aus verschiedenen Diensten und kann variabel eingesetzt werden. Je nach Anwendungsfall wählt man die geeignete Architektur, um seine Daten auswerten zu können. Im Folgenden gehen wir konkreter auf die verschiedenen Dienste in Azure Synapse ein.
Aus welchen Diensten besteht Azure Synapse Analytics?
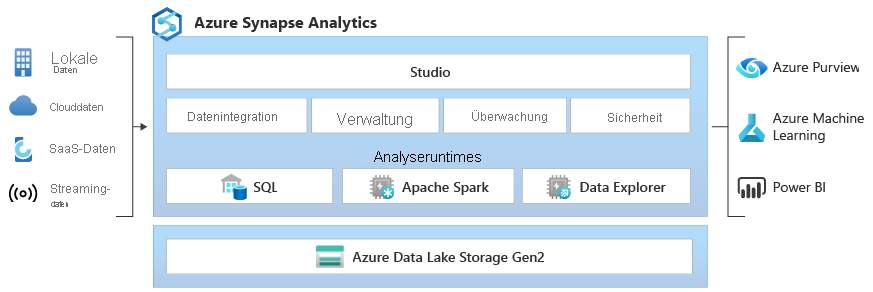
Die Plattform besteht aus dem Studio, hier kann man die Daten integrieren, verwalten, überwachen und die Sicherheit definieren. Das Studio ist die Oberfläche, auf welcher man mit den Daten arbeiten kann.
Die Daten können aus den Quellsystemen in einem Data Lake gespeichert werden. Quellsysteme können lokale Daten(banken), Clouddaten, SaaS-Daten oder auch Streamingdaten sein. Grundsätzlich spielt es keine Rolle, ob die Daten strukturiert, teilstrukturiert oder unstrukturiert sind.
Was bedeutet «strukturierte Daten» und «unstrukturierte Daten»?
Ein Blick auf den Wikipedia-Eintrag zu unstrukturierten Daten schafft schnell die nötige Klarheit:
Unterschieden werden unstrukturierte Daten von strukturierten und semistrukturierten Daten. Betrachtet man eine E-Mail, so liegt diese in einer gewissen Struktur vor: Sie enthält einen Empfänger, einen Absender und eventuell einen Titel. Damit gehört sie zu den semistrukturierten Daten. Der Inhalt der E-Mail selbst ist jedoch strukturlos.
Die automatische Nutzbarkeit unstrukturierter Daten ist dadurch eingeschränkt, dass für sie kein Datenmodell und meist auch keine Metadaten vorliegen. Auch in Textdokumenten sind Metadaten und Daten vermischt. Um Strukturen daraus zu gewinnen, ist Modellierung erforderlich. Des Weiteren wird von unstrukturierten Daten im Zusammenhang mit der Ablage von Dokumenten ohne vorhandenem Data-Warehousing gesprochen. Dadurch sind diese nicht indizierbar und können dementsprechend nicht gemeinsam durchsucht werden.
Was ist der Unterschied zwischen Data Lake und Data Warehouse?
Ein Data Warehouse speichert bereinigte und transformierte Daten. Aus diesen Daten werden Reports und Visualisierungen für Endanwender erstellt. In einen Data Lake werden Daten in ihrer Rohform geladen. Der Ladevorgang benötigt also keine Transformierung der Daten.
Beim Data Warehouse verwendet man das «Schema-on-write». das bedeutet, die Daten werden vor dem Laden (aus dem Quellsystem ins Data Warehouse) in ein vordefiniertes Schema überführt.
Beim Data Lake hingegen werden die Daten in Rohform geladen. Die Struktur und Quelle der Daten sind egal, erst bei Verwendung der Daten werden diese aufbereitet. Dieser Vorgang wird «Schema-on-read» genannt.
Beide Systeme haben das Ziel, Daten zu speichern, um daraus Informationen und Erkenntnisse zu gewinnen. Ein Data Lake ist kein «besseres» Data Warehouse, sondern ist für einen anderen Anwendungszweck optimiert. Jedes Unternehmen sollte daher die für sich passende Lösung auswählen, abhängig vom Ziel und Anwendungsfall.
Was ist SQL?
Unsere digitale Welt baut auf relationalen Datenbanken auf. Das sind zumeist SQL-Datenbanken. Oracle und Microsoft begangen schon früh mit den ersten Konzepten zu SQL-Datenbanken. Nach wie vor setzen wir auch heute noch grösstenteils diese Datenbankentechnologien ein. Structured Query Language bedeutet strukturierte Abfragesprache. Kurzum, SQL bietet die Möglichkeit, Daten abzufragen und zu strukturieren.
Was ist Apache Spark?
Apache Spark ist ein Open Source Projekt für die Big Data Analyse, Datenaufbereitung, Datentechnik, ETL (Extract, Load, Transform von Daten) und maschinelles Lernen.
Je nach Daten und Anwendungsfall gibt es die jeweils beste Technologie für den entsprechenden Bereich:
- SQL-Technologie für Data Warehousing in Unternehmen
- Spark-Technologie für Big Data-Zwecke
- Data Explorer für die Analyse von Protokollen und Zeitreihen
Der Data Explorer ermöglicht es, diese Riesenmenge an strukturierten, halbstrukturierten und Freitext-, Telemetrie- und Zeitseriendaten (IoT-Sensoren, App-/Web-/Infra-Protokollen, Sicherheitsprotokolle, etc.) abzufragen.
Azure Synapse als Low-Code Applikation?
Azure Synapse soll also eine «one System to rule them all-Lösung» in Bezug auf Business Analytics und Data werden oder sein.
Wie Kim Manis, Director of Product for Azure Synapse in einem Interview sagte, sollen in Zukunft vermehrt Low-Code/No-Code Möglichkeiten in Azure Synapse entstehen. Das Auswerten mit Daten soll dem normalen Power BI User keine Schwierigkeiten bereiten oder Expertise verlangen und sich deutlich vereinfachen. So bietet Synapse beispielsweise bereits heute Vorlagen zu Datenschemas an. Je nach Branche wählt man dann eine branchenspezifische Vorlage aus und muss nicht von Null starten. Dadurch soll die Integration verschiedener Datenquellen erleichtert werden.
Auch die Verzahnung von Dataverse und Azure Synapse über «Azure Synapse Link» zeigt die Richtung von Microsoft auf. Diese Funktion ermöglicht es, Dataverse-Daten automatisch in Azure Synapse zu bringen, um erweiterte Analyseaufgaben durchzuführen. Mit wenigen Klicks landen die Daten aus Dataverse in Azure Synapse und können dort analysiert werden, ohne die operativen Datenbanken unnötig zu belasten – ohne ETL-Prozesse, Pipelines oder Verwaltungsaufwand.
Der Low-Code Ansatz macht in Anbetracht der Power Platform-Strategie mit Dataverse, Power Apps, Power BI und Power Automate durchaus Sinn, jedoch stösst man als Endnutzerin oder Endnutzer (genau wie beim Bau von Power Apps) schnell an Grenzen.
Für wen eignet sich denn nun Azure Synapse?
Fassen wir zusammen: Azure Synapse macht an sich nichts Neues. Es vereint bereits existierende BI-Tools unter einer Plattform und spricht damit jeweilige Rollen im Bereich Business Intelligence und Daten Analyse an. Azure Synapse kann unabhängig davon genutzt werden, ob man beispielsweise ein Machine Learning Modell entwickeln oder ein Datawarehouse aufbauen möchte. Die Werkzeuge dafür stehen zur Verfügung. Grundsätzlich ist wie bei jedem anderen Tool oder Sammelsurium an Tools wichtig zu verstehen, welche Tools zur Person und deren Fähigkeiten passt. Daher langsam herantasten und die Tools kennenlernen. Ebenfalls ist die Wartbarkeit und Performance der verwendeten Tools zu berücksichtigen. Man sollte nur so viele Komponente wie notwendig verwenden, um die Komplexität gering zu halten. Frei nach dem Motto: «Weniger ist mehr!»




Beitrag teilen
Geschrieben von
Marco Jost
Projektleiter
Profil anzeigen